隨著人工智慧(AI)技術快速發展,無論是訓練 ChatGPT 等大型語言模型(Large Language Models, LLM),或是進行高效能推論運算,系統除了需要 GPU 提供強大的平行運算能力外,記憶體的資料存取效能同樣成為關鍵瓶頸。其中,高頻寬記憶體(HBM)已成為 AI 顯示卡與 AI 加速器不可或缺的核心元件,負責即時儲存並供應大量運算資料。全球 AI 晶片龍頭輝達(NVIDIA)的高階顯示卡與加速器產品,也全面導入 HBM 架構。
相較於傳統型 DRAM,HBM 的單位成本較高,價格往往高出數倍,且近年來隨著 AI 算力需求快速成長而持續上漲。目前全球 HBM 市場由 SK 海力士(SK Hynix)居於領先地位,在市占率與技術成熟度上皆具優勢;三星(Samsung)與美光(Micron)則緊追在後。面對 AI 運算需求的長期成長趨勢,三大記憶體廠皆積極擴充產能,並加速布局下一代 HBM4 產品。
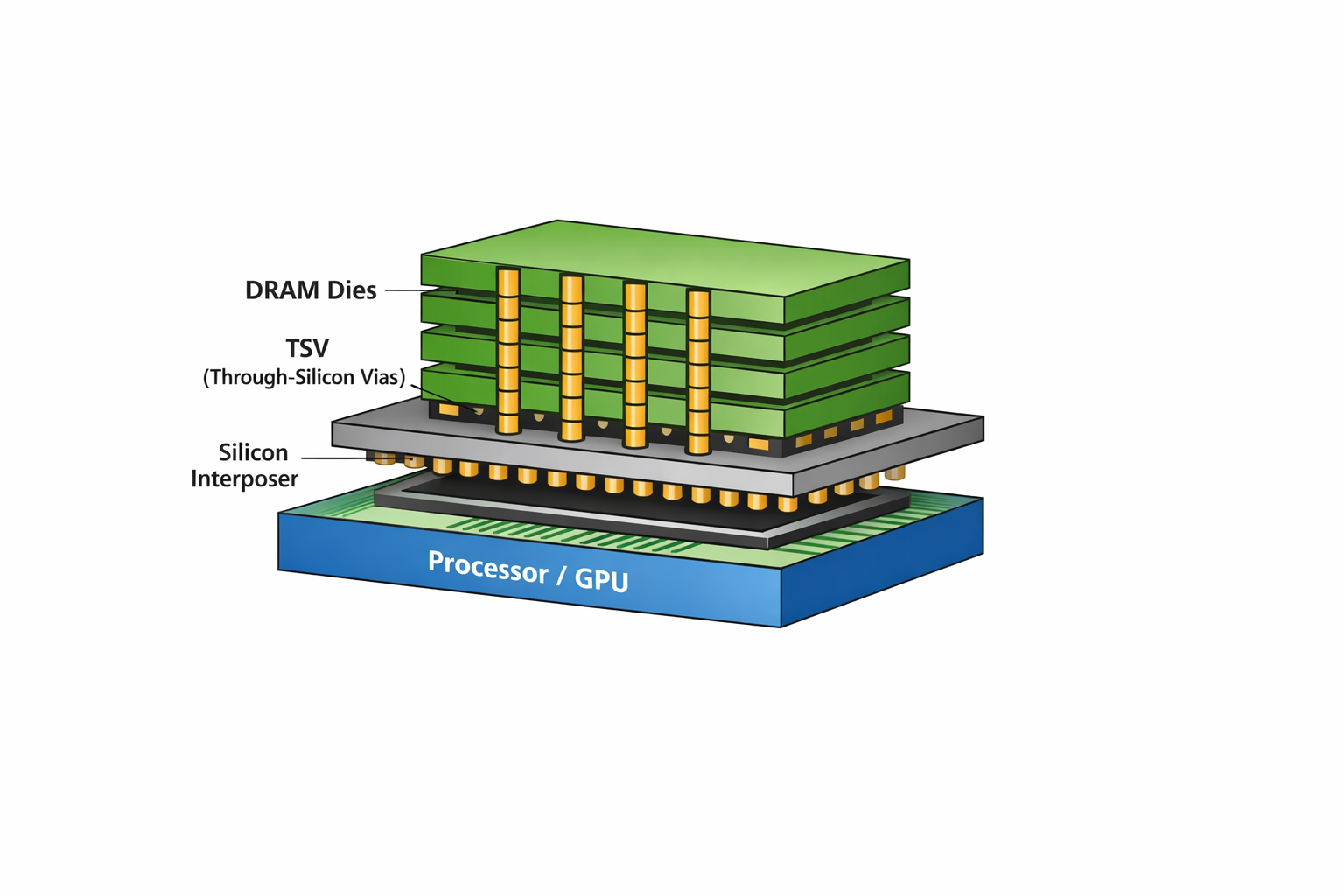
HBM 能夠大幅提升 AI 運算效能,關鍵在於其結構設計。HBM 採用多層 DRAM 晶片進行垂直堆疊,並透過矽穿孔(Through-Silicon Via, TSV)技術,將各層晶片直接連接,使資料能在晶片間高速上下傳輸。相較傳統 DRAM,HBM 可提供數倍以上的記憶體頻寬,有效降低資料存取延遲,讓 AI 模型運算更加順暢。
除了高頻寬特性外,HBM 在能效表現與功耗控制上亦具明顯優勢,非常適合資料中心、AI 伺服器、自駕車運算平台等高效能應用場景。由於體積小、效能密度高,HBM 可透過先進封裝技術,將記憶體與 GPU 或 AI 處理器緊密整合,不僅節省系統空間,也有助於提升整體運算效能。
然而,HBM 的製造門檻相當高。首先,每一層 DRAM 晶片的厚度需精準控制在數十微米等級,任何厚度偏差都可能影響堆疊品質;同時,微米級的 TSV 若無法精準對位,將導致電性失效,使整顆 HBM 堆疊無法正常運作。此外,高效能也伴隨高熱密度,多層堆疊所產生的熱量相當可觀,使散熱設計成為 HBM 與 AI 晶片發展中不可忽視的關鍵挑戰,也進一步帶動先進封裝與高效散熱技術的重要性。
隨著 AI 晶片持續朝向高效能、高整合方向演進,HBM 不僅是一項記憶體技術的突破,更結合了製程、封裝與散熱等多項關鍵技術,未來仍將是 AI 基礎運算架構中不可或缺的核心要素。